
Article 5. Comment déterminer les mots clés les plus utilisés dans la description des positions et intégrer aussi une nouvelle fonction : la fonction de traduction.
Nettoyage des données
DIR = '/content/gdrive/MyDrive/votreProjet'
file = os.path.join(DIR,'Connections.csv')
df_Connections = pd.read_csv(file)
Dans le cadre de notre démarche de nettoyage des données, nous utilisons plusieurs fonctions clés que nous avons développées antérieurement :
- clean_texte
- clean_Dataframe
- Lemmatiser
Nous complétons ces fonctions par la fonction traduire_colonne.
Bon à savoir : les fonctions de nettoyage traitent de manière assez brute les caractères spéciaux. Ces éléments - souvent considérés comme indésirables ou superflus - peuvent être cruciaux dans certaines catégories de données. Par exemple : les URL, intégrantes de notre ensemble de données, sont peuplées de caractères spéciaux indispensables à leur structure et fonctionnement.
Plusieurs étapes
Notre stratégie consiste alors à isoler initialement les colonnes contenant des données délicates - telles que les URL et les dates de connexion. Cette étape permet de les mettre à l'écart temporairement, assurant ainsi leur intégrité tout au long du processus de nettoyage. Une fois cette opération achevée, ces données sont soigneusement réintégrées au sein du dataset nettoyé.
Mise à l'isolement des colonnes
df_URL = df_Connections[['URL','Connected On']]
df_To_Clean= df_Connections.drop(['URL','Connected On'],axis=1)
Nettoyage du DataFrame
df_connections_cleaned = clean_dataframe(df_To_Clean,stopWords)
df_connections_cleaned = df_connections_cleaned.applymap(lambda x: Lemmatiser(x))
Réintégration des données isolées
df_connections_cleaned = pd.concat([df_connections_cleaned,df_URL],axis=1)
Fonction traduction
Nous nous apprêtons maintenant à focaliser notre attention sur la colonne "position" de notre dataframe. Ce segment présente des informations rédigées dans une variété de langues, bien que le français et l'anglais y soient prédominants. Pour affiner notre analyse et harmoniser notre base de données, il devient impératif d'uniformiser le langage des données. C'est ici qu'intervient notre outil : la fonction de traduction.
def traduire_colonne(df, nom_colonne):
traducteur = GoogleTranslator(source='auto', target='fr')
textes_a_traduire = df[nom_colonne].tolist()
textes_traduits = traducteur.translate_batch(textes_a_traduire)
df[f'{nom_colonne}_traduction'] = textes_traduits
return df
Comment fonctionne la fonction traduire_colonne ?
Réception des oaramètres : la fonction commence par accepter deux paramètres essentiels - le dataframe sur lequel nous souhaitons agir et la colonne spécifique destinée à la traduction.
Utilisation de Google Translate : pour la traduction, notre outil s'appuie sur la bibliothèque Google Translator, que nous avons intégrée à notre environnement de travail en amont. Cette bibliothèque puissante grâce à sa capacité à détecter automatiquement la langue source des données, éliminant ainsi le besoin de spécifier manuellement cette information, nous indiquons seulement la langue de destination ici le français.
Transformation en liste : avant la traduction, les données de la colonne ciblée sont converties en liste à l'aide de la fonction tolist(). Cette conversion facilite le traitement des données par la fonction de traduction.
Processus de traduction : la liste obtenue est ensuite passée à la fonction de traduction fournie par Google Translator. Ce processus se charge de traduire chaque élément de la liste de sa langue originale vers le français.
Création d'une nouvelle colonne : une fois la traduction terminée, les résultats sont rassemblés dans une nouvelle colonne au sein de notre dataframe. Cette colonne vient enrichir notre jeu de données.
df_Positions_Traduit = traduire_colonne(df_connections_cleaned,'Position')
df_Positions_Traduit.to_csv(f'{DIR}/Positionstraduites_linkedin.csv', index=False)
Après avoir nettoyé le dataframe "connection", nous appliquons la fonction de traduction sur la colonne "position". Une fois cette opération réalisée, pour gagner du temps et éviter de refaire la traduction à chaque utilisation, qui est une opération plutôt longue en temps, nous exportons le dataframe mis à jour directement sur notre drive. Cela nous permet de conserver une version traduite et prête à l'emploi.
Après avoir nettoyé les données… encore du nettoyage !
Avec la traduction du champ "position", nous avons observé l'apparition de nouveaux mots de faible valeur ajoutée. Pour garantir la cohérence et la qualité de notre jeu de données, une nouvelle phase de nettoyage s'impose sur notre dataframe déjà traduit.
Le processus se poursuit par la transformation de la colonne concernée en une chaîne de caractères. Nous appliquons ensuite la fonction de tokenisation, qui nous permet de séparer les mots contenus dans cette chaîne. Cette étape produit une liste de mots, ou tokens, que nous devons à nouveau convertir en dataframe, pour que les données soient compatibles avec les outils d'analyse de pandas, facilitant ainsi leur exploitation et l'extraction d'insights pertinents.
Re nettoyage
df_Position_Clean = clean_dataframe(df_Position_Traduit,stopWords)
df_Position_Lemmatizer = df_Position_Clean.applymap(lambda x: SpacyLemmatizerFR(x))
Tokenisation
Position_token = tokenisation(df_Position_Lemmatizer['traduction'])
Recomposition en dataframe
df_Positions_Token = pd.DataFrame(Position_token , columns=['Position']).reset_index()
L'analyse
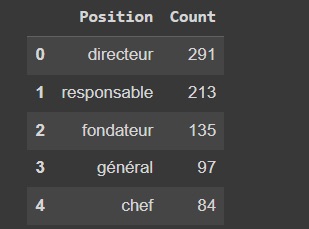
Une fois la chose faite nous comptons donc le nombre d'occurrence des modes en position pour nos 1500 contacts et nous les trions en ordre décroissant ce qui me donne le résultat suivant :
df_Position_Count = df_Positions_Token.groupby('Position')['index'].nunique().sort_values(ascending=False).reset_index()
df_Position_Count = df_Position_Count.rename(columns={'index':'Count'})
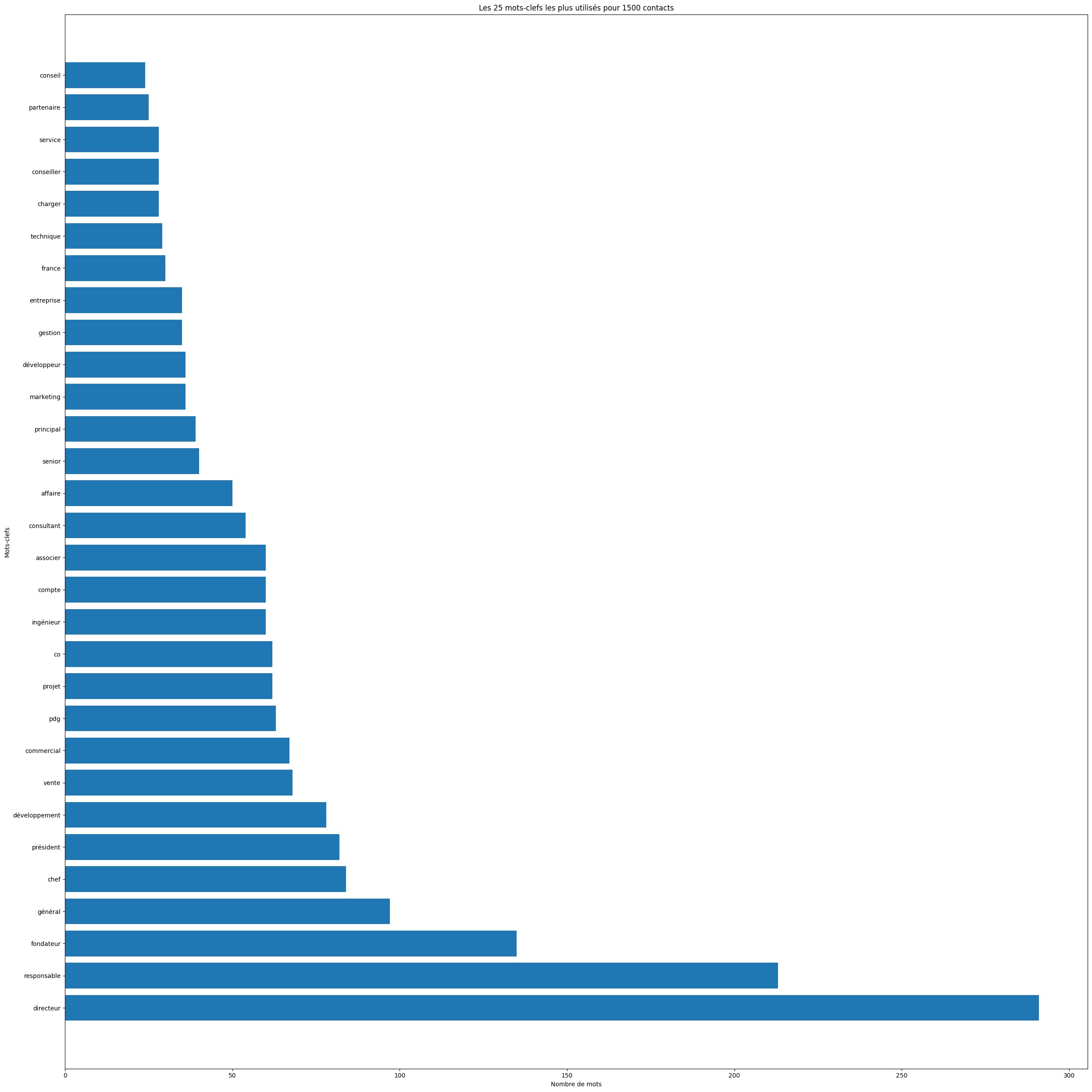
Le graphe
Il ne reste plus qu'à traiter ces informations dans un graphique avec la bibliothèque matplotlib (Comment nettoyer ses CSV ?)
Sélection des données
On commence par extraire les 30 premières lignes du DataFrame.
df_Position_Top = df_Position_Count.head(30)
Préparation du graphique
initialise une nouvelle figure pour le graphique avec une taille spécifiée de 25x25 pouces. Cette grande taille est choisie pour assurer une visibilité claire de chaque mot-clé et de sa fréquence.
plt.figure(figsize=(25, 25))
Création du graphique en barres horizontales
On crée un graphique en barres horizontales plt.barh où l'axe des y est marqué par les positions et l'axe des x par le nombre d'occurrences de chaque mot-clé.
plt.barh(df_Position_Top['Position'], df_Position_Top['Count'])
Ajout des titres et des étiquettes
plt.titleajoute un titre au graphique.plt.ylabelétiquette l’axe des y etplt.xlabell'axe des x.
plt.title('Les 25 mots-clefs les plus utilisés pour 1500 contacts')
plt.ylabel('Mots-clefs')
plt.xlabel('Nombre de mots')
Optimisation de la mise en page
plt.tight_layout() est appelé pour ajuster automatiquement les sous-plots afin qu'ils s'inscrivent dans la zone de la figure. Cela aide à s'assurer que le graphique est bien organisé et que tous les éléments sont clairement visibles.
plt.tight_layout()
Affichage du graphique
Enfin, plt.show() est utilisé pour afficher le graphique à l'écran.
plt.show()
En conclusion
Nous avons examiné les mots clés les plus fréquemment utilisés.
Notre deuxième constatation est que l'analyse de ces mots clés peut révéler des aspects de votre profil socio-professionnel.
Cela offre également l'opportunité de repenser votre stratégie de mise en réseau.
Vous pourriez envisager, selon vos objectifs professionnels, d'augmenter la présence de mots clés liés à :
- un secteur spécifique (comme la sécurité ou la technique),
- une fonction (telles que les finances),
- un niveau hiérarchique (comme fondateur).